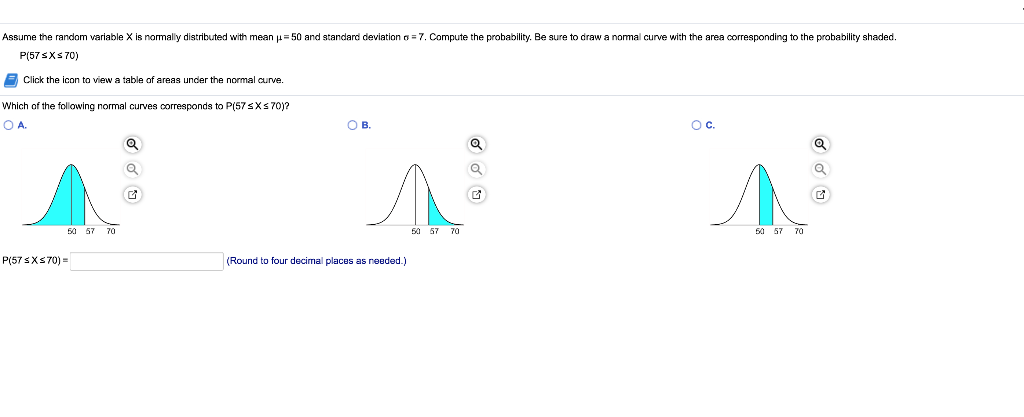
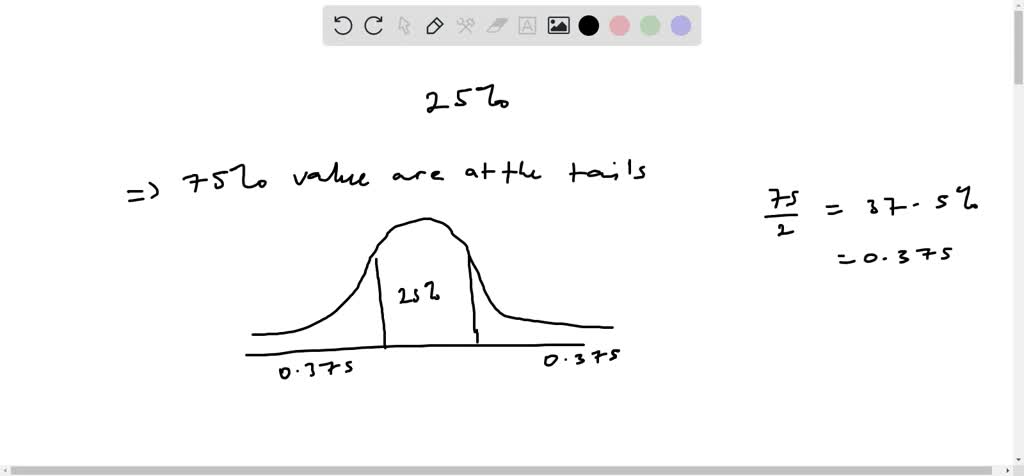
Find The Z Scores That Separate The Middle

Ever wondered how your score on a test stacks up against the rest of the class, or how tall you are compared to the average person? That's where a little statistical magic comes in, and today, we're going to pull back the curtain on a really cool concept that helps us understand where we fit in: z-scores. Don't let the fancy name fool you; it's actually a super helpful tool that can make sense of all sorts of data, from your exam results to the everyday observations around you. Think of it as your personal benchmark creator, giving you a clear picture of your position within a group. It's like having a universal translator for numbers, allowing you to compare apples and oranges (or in this case, different types of data) with confidence.
The main reason this is so neat is that raw scores often don't tell the whole story. Imagine two students, Alex and Ben, both scoring 85 on a math test. Alex's teacher reports that 85 is the highest score, while Ben's teacher mentions that 85 is just average. Suddenly, that 85 means something completely different for each of them! This is where z-scores step in to save the day. A z-score tells you how many standard deviations a particular data point is away from the mean (which is just the average of all the data points). It's a way of standardizing scores so you can make meaningful comparisons, even if the original tests or measurements had different scales, different means, or different spreads of scores.
The Power of Standardization
So, what's the big deal with z-scores? Well, their primary purpose is standardization. By converting a raw score into a z-score, you're essentially putting it on a common scale. This makes it incredibly easy to compare scores from different distributions. For instance, if you score 70 on a history test where the average was 60 with a standard deviation of 5, your z-score would be 2. Now, if you score 90 on a science test where the average was 80 with a standard deviation of 10, your z-score would also be 1. Even though the raw scores (70 and 90) are quite different, and the class averages and spreads were also different, your performance relative to your peers is actually very similar in both subjects!
Must Read
The benefits of this standardization are numerous. For students, it's a fantastic way to understand their academic performance in context. Are you excelling, or are you just meeting the average? Z-scores provide that clarity. In the professional world, businesses use z-scores to analyze sales figures, customer satisfaction surveys, and employee performance. For researchers, z-scores are fundamental in hypothesis testing and understanding the significance of their findings. It helps them determine if an observed result is likely due to chance or represents a genuine effect. Essentially, anytime you have a set of data and you want to understand where an individual piece of data sits within that set, z-scores are your go-to tool.
Finding the Middle Ground: Z-Scores for the "Middle"
Now, let's get to the fun part: finding the z-scores that separate the middle! When we talk about the "middle" of a dataset, we're often referring to the scores that are neither exceptionally high nor exceptionally low. In statistics, this middle section is typically defined by the percentage of data points it contains. For example, we might be interested in the z-scores that capture the middle 95% of the data. This means we want to find the points where 2.5% of the data lies below the lower score and 2.5% of the data lies above the upper score.
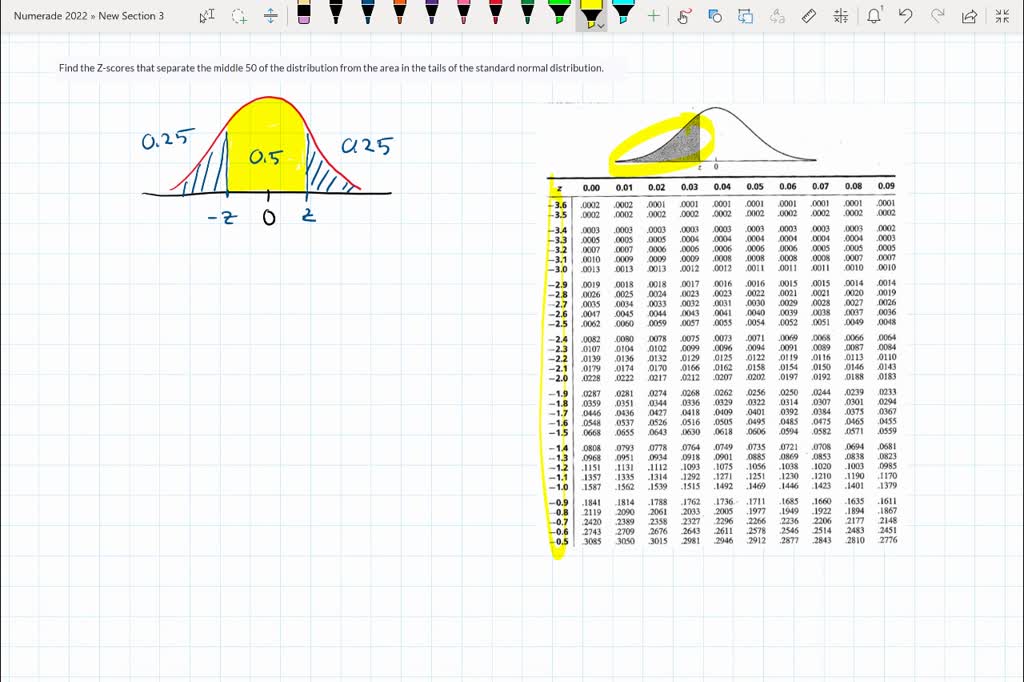
This is where the symmetry of the normal distribution, often called the bell curve, becomes incredibly useful. For a normal distribution, z-scores are symmetrically distributed around a mean of 0. A z-score of 0 means you are exactly at the average. Positive z-scores are above the average, and negative z-scores are below. When we want to find the z-scores that encompass a certain percentage of the middle data, we're essentially looking for the boundaries that leave equal amounts of data in the tails.
Let's take the classic example of the middle 95%. If 95% of the data is in the middle, that leaves 5% of the data to be distributed in the two tails (2.5% in the lower tail and 2.5% in the upper tail). Thanks to the properties of the normal distribution, we know that the z-score associated with the bottom 2.5% of data is approximately -1.96, and the z-score associated with the top 2.5% of data (which is the 97.5th percentile) is approximately +1.96. So, any data point with a z-score between -1.96 and +1.96 falls within that middle 95% of the data. This is a super common benchmark used in many statistical analyses, including constructing confidence intervals.
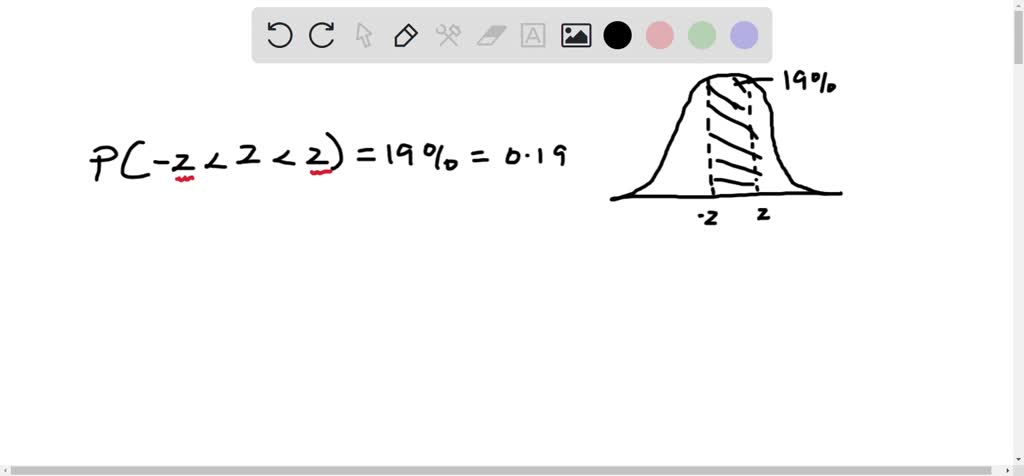
Other Common Middle Sections
But the "middle" doesn't always have to be 95%! We can define different middle sections based on our needs. For instance:
- The middle 68%: This is another key benchmark for normal distributions. It corresponds to the z-scores of -1 and +1. So, roughly two-thirds of the data falls within one standard deviation of the mean.
- The middle 90%: If we want to capture the middle 90%, we leave 5% in each tail. The z-score for the bottom 5% is approximately -1.645, and for the top 5% (95th percentile) it's approximately +1.645.
- The middle 99%: To capture the middle 99% of data, we leave 0.5% in each tail. The z-scores here are approximately -2.576 and +2.576.
These specific z-score values are often found in statistical tables or can be calculated using statistical software. They act as critical thresholds that help us understand the spread and central tendency of our data. Whether you're trying to identify typical performance levels, set quality control limits, or simply understand what "average" really means in a statistical sense, knowing these z-scores for the middle is incredibly powerful. It’s a simple yet profound way to bring clarity and meaning to the numbers that surround us every day!